玄宇芯大模型推理加速卡,专为大规模语言模型高效推理设计的一款全自研大模型推理卡。
玄宇芯推理卡是专为大规模语言模型高效推理设计的一款全自研大模型推理卡。产品集成自研LPU,通过软硬协同优化,实现高性能、低功耗的AI推理。研发初衷旨在通过超高性价比,加速不同行业AI应用的低成本落地。
二、核心优势
2.1 专用LPU架构
摒弃通用GPU设计,自主研发LPU: “Language Processing
Unit”,针对Transformer类模型的稀疏计算、低精度运算和注意力机制深度优化 。
2.2 高算力密度
专用高速处理单元与HBM,可最大限度减少数据搬移与内存访问延迟。
2.3 可扩展集群
多芯片互联,实现近线性扩展,满足大规模部署需求。
2.4 低功耗混合精度
原生支持INT2/INT4/INT8等动态精度调度,在保证精度的前提下进一步压榨性能/功耗比
2.5 兼容性与易集成
无缝对接主流AI框架与中间件,部署维护简便,延迟可控。
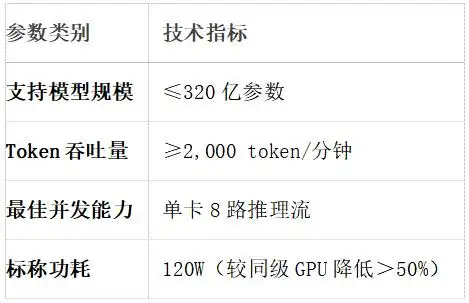
三、产品参数
四、多元应用场景
4.1 在线智能客服系统
单卡支持 8 路推理流的高并发能力,可同时响应 8 个用户的实时咨询;≥2000 token / 分钟的吞吐速率确保对话无卡顿,配合专用 LPU
对 Transformer 的优化,能精准理解用户意图(如复杂问题拆解、多轮对话上下文关联),相较传统 GPU 方案,120W 低功耗可降低数据中心 70%
的能耗成本,尤其适合电商、金融等客服咨询量密集的行业。
4.2 直播平台实时互动助手
支持实时弹幕内容审核、主播话术建议等低延迟场景(端到端延迟波动≤±5ms),无缝对接直播平台中间件;ROI
处理加速器优先保障主播与观众的交互响应,120W 功耗适配边缘节点部署,单卡可支撑 3-5 个直播间的实时 AI 服务,较同级 GPU 方案硬件成本降低
40%,且易集成特性可快速对接现有直播系统。
4.3 企业级智能知识库问答
针对企业内部文档(如技术手册、流程规范)的多轮问答场景,专用 LPU
对注意力机制的优化可提升长文本上下文理解能力;可快速部署企业私有知识库模型,8 路并发满足中小型企业全员查询需求,低功耗设计适合办公区边缘部署,无需改造现有供电系统。
五、售后支持
如需产品配套资料,可直接联系客服领取。专业团队提供全方位技术支持服务,包括硬件定制、算法适配等商业服务,助力项目顺利落地。
文章来源:https://www.honganinfo.com/computing-power/inference-chip/