Xuanyu 大模型 Inference Acceleration Card is a fully self-developed LLM inference card designed for efficient inference of large language models.
The Xuanyu Inference Card is a fully self-developed LLM inference card designed for efficient inference of large language models. The product integrates a self-developed LPU and achieves high-performance, low-power AI inference through software-hardware collaborative optimization. The original intention of R&D is to accelerate the low-cost implementation of AI applications in various industries through ultra-high cost performance.
II. Core Advantages
2.1 Dedicated LPU Architecture
Abandoning general-purpose GPU design, independently developed LPU: "Language Processing Unit", deeply optimized for sparse computation, low-precision operations, and attention mechanisms of Transformer models.
2.2 High Computing Power Density
Dedicated high-speed processing units and HBM can minimize data movement and memory access latency.
2.3 Scalable Cluster
Multi-chip interconnection achieves near-linear scalability to meet large-scale deployment needs.
2.4 Low Power Hybrid Precision
Natively supports dynamic precision scheduling such as INT2/INT4/INT8, further squeezing the performance/power ratio while ensuring accuracy.
2.5 Compatibility and Easy Integration
Seamlessly connects with mainstream AI frameworks and middleware, easy to deploy and maintain, and controllable latency.
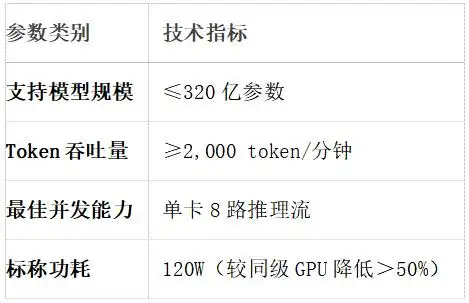
III. Product Parameters
IV. Diverse Application Scenarios
4.1 Online Intelligent Customer Service System
A single card supports high concurrency of 8 inference streams, capable of responding to 8 users' real-time consultations simultaneously; ≥2000 tokens/min throughput ensures smooth conversations. With dedicated LPU optimization for Transformer, it can accurately understand user intentions (such as complex problem decomposition and multi-turn dialogue context association). Compared with traditional GPU solutions, 120W low power consumption can reduce data center energy consumption costs by 70%, especially suitable for industries with intensive customer service consultations such as e-commerce and finance.
4.2 Real-time Interactive Assistant for Live Streaming Platforms
Supports low-latency scenarios such as real-time barrage content review and host speech suggestions (end-to-end latency fluctuation ≤±5ms), seamlessly connects with live streaming platform middleware; ROI processing accelerator gives priority to host and audience interaction response, 120W power consumption is suitable for edge node deployment, a single card can support real-time AI services for 3-5 live rooms, hardware cost is reduced by 40% compared to similar GPU solutions, and the easy integration feature can quickly connect to existing live streaming systems.
4.3 Enterprise-level Intelligent Knowledge Base Q&A
For multi-turn Q&A scenarios of internal enterprise documents (such as technical manuals and process specifications), dedicated LPU optimization for attention mechanisms can improve long-text context understanding; enterprise private knowledge base models can be quickly deployed, 8-way concurrency meets the query needs of all employees in small and medium-sized enterprises, and the low-power design is suitable for edge deployment in office areas without modifying the existing power supply system.
V. After-sales Support
For product supporting materials, you can directly contact customer service to receive them. The professional team provides comprehensive technical support services, including hardware customization, algorithm adaptation and other commercial services, to help projects land smoothly.
Source: https://www.honganinfo.com/computing-power/inference-chip/